

 如果结果不匹配,请
如果结果不匹配,请 
 更多“完全二叉树某结点有右子树,则必然有左子树。()”相关的问题
更多“完全二叉树某结点有右子树,则必然有左子树。()”相关的问题
根结点的数据,LT和RT是括号形式的左子树和右子树。要求空树不打印任何信息,一个结点的树的打印形式是x,而不应是(x,)的形式。
A.二叉树中每个结点有两个子结点,而树无此限制,因此二叉树是树的特殊情况
B.当K≥1时高度为K的二叉树至多有2k-l个结点
C.将一棵树转换成二叉树后,根结点没有左子树
D.哈夫曼树是带权路径最短的树,路径上权值较大的结点离根较近
以二叉链表作为二叉树的存储结构,编写以下算法:
(1)统计二叉树的叶结点个数。
(2)设计二叉树的双序遍历算法(双序遍历是指对于二叉树的每一个结点来说,先访问这个结点,再按双序遍历它的左子树,然后再一次访问这个结点,接下来按双序遍历它的右子树)。
(3)计算二叉树最大的宽度(二叉树的最大宽度是指二叉树所有层中结点个数的最大值)。
(4)用按层次顺序遍历二叉树的方法,统计树中具有度为1的结点数目。
(5)求任意二叉树中第一条最长的路径长度,并输出此路径上各结点的值。
(6)输出二叉树中从每个叶子结点到根结点的路径。
判断下列叙述的对错,
(1)若有一个结点是二叉树中某个子树的中序遍历结果序列的最后一个结点,则它一定是该子树的前序遍历结果序列的最后一个结点。
(2)若有一个结点是二叉树中某个子树的前序遍历结果序列的最后一个结点,则它一定是该子树的中序遍历结果序列的最后一个结点。
(3)若有一个叶子结点是二叉树中某个子树的中序遍历结果序列的最后一个结点,则它一定是该子树的前序遍历结果序列的最后一个结点。
(4)若有一个叶子结点是二叉树中某个子树的前序遍历结果序列的最后一个结点,则它一定是该子树的中序遍历结果序列的最后一个结点。
A.二叉树的度为2
B.只有一个结点的二叉树的度为1
C.二叉树的左右子树可任意交换
D.深度为K的完全二叉树的结点个数小于或等于深度相同的满二叉树的结点个数
针对一棵序线索二叉树:
(1)编写算法,实现二叉树到后序线索二叉树的转换;
(2)编写算法,求以t为根的子树的后序下的第一个结点;
(3)编写算法,求以t为根的子树的后序下的最后一个结点;
(4)编写算法,求结点t的后序下的后继结点;
(5)编写算法,求结点t的后序下的前驱结点;
(6)编写算法,实现后序线索二叉树的后序遍历
所谓半无穷范围查询(semi-infinite range query),是教材8.4节中所介绍一般性范围查询的特例,具体地,这里的查询区域是某一侧无界的广义矩形区域,比如R=[-1,+1]x[0,﹢∞),即是对称地包含正半y坐标轴、宽度为2的一个广义矩形区域,当然,对查询的语义功能要求依然不变——从某一相对固定的点集中,找出落在任意指定区域R内部的所有点。
范围树(176页习题[8-20])稍作调整之后,固然也可交持半无穷范围查询,但若能针对这一特定问题所固有的性质,改用优先级搜索树(priority search tree,PST)之类的数据结构,则不仅可以保持O(r+logn)的最优时间效率,而且更重要的是,可以将空间复杂度从范围树的O(nlogn)优化至O(n)。
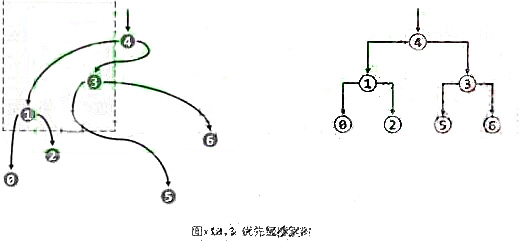
如图x10.3所示,优先级搜索树除了首先在拓扑上应是一棵二叉树,还同时遵守以下三条规则。
①首先,各节点的y坐标均不小于其左右孩子(如果存在)——因此,整体上可以视作为以y坐标为优先级的二叉堆。
②此外,相对于任一父节点,左子树中节点的x坐标均不得大于右子树中的节点。
③最后,互为兄弟的每一对左、右子树,在规模上相差不得超过一。
a)试按照以上描述,用C/C++定义并实现优先级搜索树结构;
b)试设计一个算法,在O(nlogn)时间内将平面上的n个点组织为一棵优先级搜索树;
c)试设计一个算法,利用已创建的优先级搜索树,在O(r+logn)时间内完成每次半无穷范围查询,其中r为实际命中并被报告的点数。















