 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用BWGHT2.RAW,我们估计出下面的等式:: 式中,lbwgt为出生重量的对数;npvis为产前就诊的数量;
利用BWGHT2.RAW,我们估计出下面的等式::

式中,lbwgt为出生重量的对数;npvis为产前就诊的数量;mage为母亲的年龄;fage为父亲的年龄;meduc为母亲的受教育程度;feduc为父亲的受教育程度。括号当中是普通标准差,方括号中是异方差-稳健的标准误。
(i)解释变量cigs前面的系数。βcigs的95%置信区间是否依赖于你所选择的标准误?
(ii)使用一般标准误和异方差一稳健的标准误来解释npvis的统计显著性。
(iii)如果将四个与年龄和教育相关的项从回归方程中去掉(仍然使用同一组观测值),那么R²变为0.0162。是否有足够的信息来进行关于 的异方差-稳健性检验?请解释。
的异方差-稳健性检验?请解释。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“利用BWGHT2.RAW,我们估计出下面的等式:: 式中,l…”相关的问题
更多“利用BWGHT2.RAW,我们估计出下面的等式:: 式中,l…”相关的问题
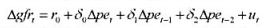
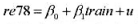 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?

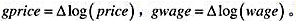 ]利用WAGEPRC.RAW中的月度数据,我们估计了如下分布滞后模型:
]利用WAGEPRC.RAW中的月度数据,我们估计了如下分布滞后模型: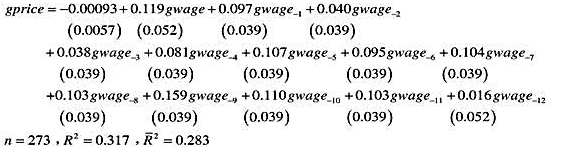
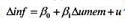 估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。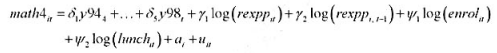
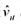 。
。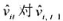 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。















