 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
Logistic回归模型适用于因变量为()。
A.分类值的资料
B.连续型的计量资料
C.正态分布资料
D.偏态分布资料
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.分类值的资料
B.连续型的计量资料
C.正态分布资料
D.偏态分布资料
如果结果不匹配,请 联系老师 获取答案
 更多“Logistic回归模型适用于因变量为()。”相关的问题
更多“Logistic回归模型适用于因变量为()。”相关的问题
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型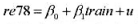 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
A、Cox regression
B、Linear regression
C、Logistic regression
D、Multiple regressions
E、Passion regression
本题利用NBASAL.RAW中的数据。
(i)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。包括打球经历的二次项形式,并将中锋作为基组。以通常的形式报告结果。
(ii)在第(i)部分中,你为什么不将所有三个位置虚拟变量包括进来?
(iii)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?
(iv)现在,将婚姻状况加入方程。保持位置和经历不变,已婚球员是否更高效(就单场得分来说)?
(v)加入婚姻状况和两个经历变量的交互项。在这个扩展的模型中,是否存在有力的证据表明婚姻状况影响单场得分?
(vi)使用单场助攻次数作为因变量估计(iv)中的模型。与(iv)的结果有明显的差异吗?请讨论。
(1)比较logistic模型与Gompertz模型: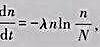 其中n(t)是细胞数,N是极限值,λ是参数。
其中n(t)是细胞数,N是极限值,λ是参数。
(2)说明上述两个模型是Usher模型: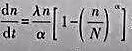 的特例。
的特例。
使用WAGE1.RAW中的数据。
(i)估计方程
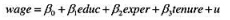
保留残差并画出其直方图。
(ii)以log(wage)作为因变量重做第(i)部分。
(iii)你认为是水平值-水平值模型还是对数-水平值模型更接近于满足假定MLR.6?
















