 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
假定AA为一个类,a()为该类公有的函数成员,x为该类的一个对象,则访问x对象中函数成员a()的格式为()。
A.x.a
B.x.a()
C.x->a
D.x->a()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.x.a
B.x.a()
C.x->a
D.x->a()
如果结果不匹配,请 联系老师 获取答案
 更多“假定AA为一个类,a()为该类公有的函数成员,x为该类的一个…”相关的问题
更多“假定AA为一个类,a()为该类公有的函数成员,x为该类的一个…”相关的问题
除留余数法构造哈希函数和线性探测法处理冲突,试求出每一元素在哈希表中的初始哈希地址和最终哈希地址,画出最后得到的哈希表,求出平均查找长度。
设计一个名为MyPoint的类表示一个具有x坐标和y坐标的点,该类包括: 两个数据域(成员变量)x和y表示坐标; 无参构造方法创建点(0,0); 一个构造方法根据指定坐标创建一个点; distance方法(static修饰)返回MyPoint类型的两个点之间的距离(方法的参数为两个MyPoint对象); distance方法返回从当前点(调用方法的对象)到另一点(方法的参数)之间的距离(方法的参数为一个MyPoint对象); 在主方法中,输入一个点,求距离原点的距离,再输入两点,求两点之间的距离。 PS:成员变量必须由private修饰,且为其定义访问方法
A.internal MyClass() {}
B.public MyClass(){Count = 0;Msg = null;}
C.public MyClass{}
D.不存在
设A={a,b},s为AA,即S={f1,f2,f3,f4},诸f由表11.4给定.

(1)给出S上的函数复合运算.的运算表
(2)是否有幺元、零元?
(3)中哪些元素有逆元?逆元是什么?
y为整数),这些函数能够当作散列函数吗(即对于插入和查找,散列程序能正常工作吗)?如果能够,它是一个好的散列函数吗?请说明理由。设函数random(m)返回一个0到m-1之间的随机整数(包括0与m-1在内)。
(1)Hash(key)==key/m;
(2)Hash(key)=1;
(3)IIash(key)==(key+random(m))%rn;
(4)Hash(key)=key%p(m);其中p(m)是不大于m的最大素数。
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
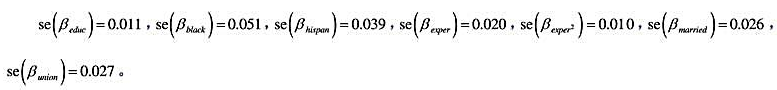
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
A.AA
B.Aa
C.aa
D.都不是
















