 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
假定AA为一个类,a为该类公有的数据成员,x为该类的一个对象,则访问x对象中数据成员a的格式为x->a。()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“假定AA为一个类,a为该类公有的数据成员,x为该类的一个对象…”相关的问题
更多“假定AA为一个类,a为该类公有的数据成员,x为该类的一个对象…”相关的问题
设计一个名为MyPoint的类表示一个具有x坐标和y坐标的点,该类包括: 两个数据域(成员变量)x和y表示坐标; 无参构造方法创建点(0,0); 一个构造方法根据指定坐标创建一个点; distance方法(static修饰)返回MyPoint类型的两个点之间的距离(方法的参数为两个MyPoint对象); distance方法返回从当前点(调用方法的对象)到另一点(方法的参数)之间的距离(方法的参数为一个MyPoint对象); 在主方法中,输入一个点,求距离原点的距离,再输入两点,求两点之间的距离。 PS:成员变量必须由private修饰,且为其定义访问方法
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
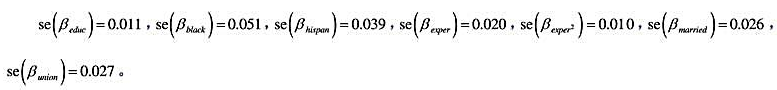
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
试用1片八D锁存器74HC373设计一个能锁存两组BCD码信号的锁存电路。假定三态输出使能端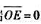 ,锁存器原输出为
,锁存器原输出为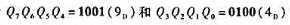 ,输入为
,输入为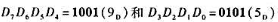 ,画出锁存器锁存新数据前、后使能端LE应输入的波形和相应Q0的波形。
,画出锁存器锁存新数据前、后使能端LE应输入的波形和相应Q0的波形。
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
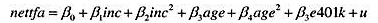
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
A.AA
B.Aa
C.aa
D.都不是
A.420
B.450
C.480
D.570
5月10日,将所持有的该股票全部出售,所得价款825万元,已存入银行.假定不考虑相关税费.
要求:逐笔编制甲上市公司上述业务的会计公录.
(会计科目要求写出明细科目,答案中的金额单位用万元表示)
















