

 如果结果不匹配,请
如果结果不匹配,请 
 更多“K-均值算法是一种产生划分聚类的基于密度的聚类算法,簇的个数…”相关的问题
更多“K-均值算法是一种产生划分聚类的基于密度的聚类算法,簇的个数…”相关的问题
第1题
下面关于K-均值聚类法的描述,正确的有()。
A.适合于大样本
B.类别数目的确定具有一定的主观性
C.事先不确定要分多少类,先把每一个对象作为一类,然后一层一层分类
D.要求研究者先指定需要划分的类别个数
E.计算量较小,效率比层次聚类要高
第2题
关于K均值和DBSCAN的比较,以下说法不正确的是()。
A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象
B.K均值使用簇的基本原型概念,而DBSCAN使用基于密度的概念
C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇
D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但DBSCAN会合并有重叠的簇
第4题
确定用于在k均值算法中找到最佳聚类的最佳方法()
A.Euclideanmethod
B.Manhattanmethod
C.Elbowmethod
D.Silhouettemethod
第6题
假定你作为一个数据挖掘顾问,受雇于一家因特网搜索引擎公司,下列属于使用数据挖掘方法为公司提供帮助的是()。
A.使用聚类算法发现互联网中的不同群体,用于网络社区发现
B.使用分类对客户进行等级划分,从而实施不同的服务
C.使用关联规则发现大型数据集中间存在的关系,用于推荐搜索
D.使用离群点挖掘发现与大部分对象不同的对象,用于分析针对网络的秘密收集信息的攻击
E.使用人工查询公司网络故障信息,查找原因进行记录
第7题
如下那些不是基于规则分类器的特点()
A.无法被用来产生更易于解释的描述性模型
B.规则集的表达能力远不如决策树好
C.基于规则的分类器都对属性空间进行直线划分,并将类指派到每个划分
D.非常适合处理类分布不平衡的数据集
第8题
在实际应用中,常需模拟服从正态分布的随机变量,其密度函数为式中,a为均值,σ为标准差.如果s和t
在实际应用中,常需模拟服从正态分布的随机变量,其密度函数为
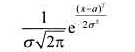
式中,a为均值,σ为标准差.
如果s和t是(-1,1)中均匀分布的随机变量,且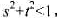 ,令
,令

则u和v是服从标准正态分布(a=0,σ=1)的两个互相独立的随机变量.
(1)利用上述事实,设计一个模拟标准正态分布随机变量的算法.
(2)将上述算法扩展到一般的正态分布.















