 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
假定你已经搜集了10000行推特文本的数据,不过没有任何信息。现在你想要创建一个推特分类模型,好把每条推特分为三类:积极、消极、中性。通过把每个推特视为一个文档,我们创建一个数据化的文档词矩阵。关于文档矩阵,以下哪项是正确的?()
A.从数据中移除停用词(stopwords)将会影响数据的维度
B.数据中词的归一化将会减少数据的维度
C.转化所有的小写单词将不会影响数据的维度
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.从数据中移除停用词(stopwords)将会影响数据的维度
B.数据中词的归一化将会减少数据的维度
C.转化所有的小写单词将不会影响数据的维度
如果结果不匹配,请 联系老师 获取答案
 更多“假定你已经搜集了10000行推特文本的数据,不过没有任何信息…”相关的问题
更多“假定你已经搜集了10000行推特文本的数据,不过没有任何信息…”相关的问题
A.完成一个主题模型掌握语料库中最重要的词汇
B.训练袋N-gram模型捕捉顶尖的n-gram:词汇和短语
C.训练一个词向量模型学习复制句子中的语境
D.以上所有
A.搜集了选题的大量相关文献
B.好的综述就是一个小型的信息源
C.因为汇集了大量参考文献,所以综述被称为二次文献
D.通过综述,可以短时间内了解选题的研究历史、发展动态、水平等
年和1995年的入学申请数据。
(i)你会怎样把度量体育成绩的变量放入方程中?有什么样的时期安排问题?
(ii)你想在方程中控制哪些其他因素?
(iii)试写出一个方程,用以估计体育成绩对申请人数百分数变化的影响。你如何估计这个方程呢?为什么选用这一方法?
(i)有多少个州在1991年、1992年和1993年中至少处决了一个犯人?哪个州处决得最多?
(ii)利用1990年和1993两年的数据, 做一个mrd rte对d93、exec和unem的混合回归。你对exec系数如何解释?
(iii)仅利用1990~1993年的变化(对总共51个观测值) , 用OLS估计以下方程
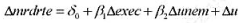
并以通常的格式报告结果。现在,处以死刑是否看起来具有威慑作用?
(iv)处决的变化至少可能部分地与预期谋杀率的变化有关, 因而△ exec与第(iii) 部分中的△u相关。假定△exec-1与△u不相关也许是合乎情理的。(毕竟, △exec-1 依赖于三年或更久以前进行的处决数。) 将△exec对△exec-1进行回归, 看它们是否充分相关:解释△exec-1的系数。
(v)用△exec-1作为△exec的Ⅳ, 重新估计第(iii) 部分中的方程。假定△mem是外生的。你从第(ii) 部分中得出的结论将怎样变化?
A.贾宪的《议古根源》
B.杨辉的《详解九章算法》
C.秦九韶的《数书九章》
D.李冶的《测圆海镜》
















