

 如果结果不匹配,请
如果结果不匹配,请 
 更多“某Excel数据表记录了学生的5门课成绩,现要找出5门课都不…”相关的问题
更多“某Excel数据表记录了学生的5门课成绩,现要找出5门课都不…”相关的问题
A.编辑
B.插入
C.格式
D.数据
A.某班级的学生成绩表是数据元素,90分是数据项
B.某班级的学生成绩表是数据对象,90分是数据元素
C.某班级的学生成绩表是数据对象,90分是数据项
D.某班级的学生成绩表是数据元素,90分是数据元素
A.有的课程没有学生选修
B.有的学生选修了3门课程
C.所有学生都选修了某门课程
D.所有课程都有学生选修
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
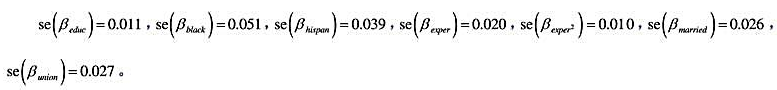
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
有以下三个基本表:
学生(学号,姓名,年级,专业)
课程(课号,课名,开课教师,学分)
选课(学号,课号,成绩)
写出相应的SQL语句:
所有90级“软件”专业学生的姓名.
已知表student(学号,姓名,性别,出生日期,专业)
course(课程号,课程名,学时数,学分)
grade(学号,课程号,成绩)、
试在所有学生的课程成绩中列出课程成绩最高的学生姓名、专业、课程名和成绩.















