

 如果结果不匹配,请
如果结果不匹配,请 
 更多“在计量经济模型中,加入虚拟变量的途径有两种基本类型:一是()…”相关的问题
更多“在计量经济模型中,加入虚拟变量的途径有两种基本类型:一是()…”相关的问题
本题利用NBASAL.RAW中的数据。
(i)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。包括打球经历的二次项形式,并将中锋作为基组。以通常的形式报告结果。
(ii)在第(i)部分中,你为什么不将所有三个位置虚拟变量包括进来?
(iii)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?
(iv)现在,将婚姻状况加入方程。保持位置和经历不变,已婚球员是否更高效(就单场得分来说)?
(v)加入婚姻状况和两个经历变量的交互项。在这个扩展的模型中,是否存在有力的证据表明婚姻状况影响单场得分?
(vi)使用单场助攻次数作为因变量估计(iv)中的模型。与(iv)的结果有明显的差异吗?请讨论。
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
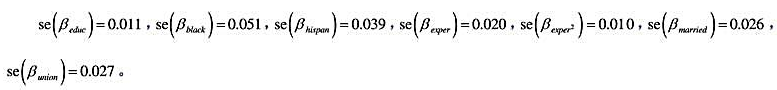
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
(i) 估计一个将respond与resplast和avggift联系起来的线性概率模型。以通常的形式报告结果, 并解释变量resplast的系数。
(ii)过去捐助的平均水平看来会影响做出捐助响应的概率吗?
(iii) 在模型中增加变量propres p并解释其系数。(这里须注意, propresp增加1是最大可能变化。)
(iv) 在回归中增加propres p以后, resp last的系数有何变化?这讲得过去吗?
(v) 在模型中增加每年寄出邮件的数量mail year。它的估计影响有多大?为什么它不是邮件数量对响应的因果关系的一个较好的估计?
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
本题利用401KSUBS.RAW中的数据。
(i) 计算样本中nettfa的平均值、标准差、最小值和最大值。
(ii) 检验假设平均nettfa不会因为401(k) 资格状况而有所不同, 使用双侧对立假设。估计差异的美元数量是多少?
(iii)根据计算机习题C7.9的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e40lk作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv) 在第(iii) 部分估计的模型中, 增加交互项e401k·(age-41) 和e401k·(age-41)2 。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi) 现在, 从模型中去掉交互项, 但定义5个家庭规模虚拟变量:fsize l, j size2,f size 3, f size 4和f size 5。对有5个或5个以上成员的家庭, fsize 5等于1。在第(iii) 部分估计的模型中, 增加家庭规模虚拟变量, 记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii) 现在, 针对模型
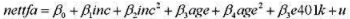
在容许截距不同的情况下, 做5个家庭规模类别的邹至庄检验。约束残差平方和SSR, 从第(vi) 部分得到,因为那里回归假定了相同斜率。无约束残差平方和SSRUR=SSR1+SSR2 +…+SSR5 , 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
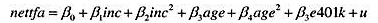
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。















