

 如果结果不匹配,请
如果结果不匹配,请 
 更多“估计的标准误差是实际观测值与回归估计值离差平方和的均方根。(…”相关的问题
更多“估计的标准误差是实际观测值与回归估计值离差平方和的均方根。(…”相关的问题
设总体X的概率密度函数为

x1,x2,...,xn是从X取出的样本观测值,求总体参数a的矩估计值和最大似然估计值。
ize) 方面的信息, 以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题, 只使用单身者数据(fsize=1)。
(i)数据集中有多少单身者?
(il)利用OLS估计模型
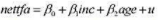
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H1:β2<1检验H0:β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归, inc的斜率估计值与第(ii) 部分的估计值有很大不同吗?为什么?
设总体X的概率密度为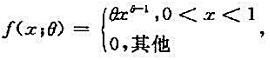 其中θ>0,若样本观测值为x1,x2,...,xn,求参数θ的矩估计值与最大似然估计值。
其中θ>0,若样本观测值为x1,x2,...,xn,求参数θ的矩估计值与最大似然估计值。
(i)有多少个州在1991年、1992年和1993年中至少处决了一个犯人?哪个州处决得最多?
(ii)利用1990年和1993两年的数据, 做一个mrd rte对d93、exec和unem的混合回归。你对exec系数如何解释?
(iii)仅利用1990~1993年的变化(对总共51个观测值) , 用OLS估计以下方程
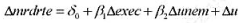
并以通常的格式报告结果。现在,处以死刑是否看起来具有威慑作用?
(iv)处决的变化至少可能部分地与预期谋杀率的变化有关, 因而△ exec与第(iii) 部分中的△u相关。假定△exec-1与△u不相关也许是合乎情理的。(毕竟, △exec-1 依赖于三年或更久以前进行的处决数。) 将△exec对△exec-1进行回归, 看它们是否充分相关:解释△exec-1的系数。
(v)用△exec-1作为△exec的Ⅳ, 重新估计第(iii) 部分中的方程。假定△mem是外生的。你从第(ii) 部分中得出的结论将怎样变化?
利用数据集GPA1.RAW。
(i)利用OLS估计一个将colGPA与hsGPA,ACT,skipped和PC相联系的模型。求OLS残差。
(ii)计算异方差性的怀特检验特殊情形。在对colGPA,和colGPA,的回归中,求拟合值。
(iii)验证第(ii)部分得到的拟合值都严格为正。然后利用权数1/h求加权最小二乘估计值。根据对应的OLS估计值,将逃课和拥有计算机之影响的加权最小二乘估计值与对应OLS估计值相比较。它们的统计显著性如何?
(iv)在第(iii)部分的WLS估计中,求异方差-稳健的标准误。换言之,容许第(ii)部分中所估计的方差函数可能误设(参见问题8.4)。标准误与第(iii)部分相比有很大变化吗?
利用数据集401KSUBS.RAW。
(i)利用OLS估计e401k的一个线性概率模型,解释变量为inc,inc²,age,age²和male。求通常的OLS标准误和异方差-稳健的标准误。它们有重要差别吗?
(iii)对第(i)部分估计的模型求怀特检验,并分析系数估计值是否大致对应于第(ii)部分中描述的理论值。
(iv)在验证了第(i)部分的拟合值都介于0和1之间后,求这个线性概率模型的加权最小二乘估计值。它们与OLS估计值有重大差别吗?
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型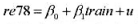 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
使用LOANAPP.RAW中的数据。
(i)有多少个观测的obrat>40,即其他债务负担超过其总收入的40%?
(ii)在第7章的计算机练习C8中,去掉obrat>40的观测,重新估计第(ii)部分中的模型。white的系数估计值和:统计量将会怎样?
(ii)βwhite看起来对所使用的样本过度敏感吗?















