 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不是这个过程的一部分()
A.数据标准化
B.教据降维
C.数据可视化
D.数据清理
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.数据标准化
B.教据降维
C.数据可视化
D.数据清理
如果结果不匹配,请 联系老师 获取答案
 更多“机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不…”相关的问题
更多“机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不…”相关的问题
A.ECA加流量检测最核心的技术是生成ECA检测分类模型
B.通过前端ECA探针提取加密流量的明文数据,包括TLS握手信息、TCP统计信息、DNS/HTTP相关信息,并将它们统一上报给CIS系统
C.基于分析取证的特征向量,采用机器学习的方法,利用样本数据进行训练,从而生成分类器模型
D.安全研究人员通过和群殴的黑白样本集,结合开源情报,域名,IP,SSL等信息,提取加密流量的特性信息
A.帮助我们关注数据的细节,可以获知个体信息
B.帮助我们从不同维度观察汇总数据
C.帮助我们回答决策/预测层次的问题
D.借助AI、机器学习等方法由计算机从数据中自动揭示事物规律
A.通常被放入干燥机的金属厚度与大多数大头针基本相同
B.将来的消费者经常用机器干燥的许多衣服包括粗金属部件,如装饰性的黄铜饰钉或纽扣
C.该实验性的微波干燥机比未来预期要使用的改良模型消耗更多的电力
D.利用该程序干燥衣服导致的缩水程度小于目前使用的机械干燥程序
利用PHILLIPS.RAW中的数据,但只到1996年。
(i)在教材例11.5中,我们假定自然失业率是常数。在另一种形式的附加预期的菲利普斯曲线中,自然失业率受历史失业水平的影响。最简单的情况是,t时期的自然失业率与unemt-1,相等。如果我们假定适应性预期,便得到一个通货膨胀和失业率都是一阶差分形式的菲利普斯曲线: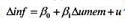 估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
(ii)教材(11.19)和第(i)部分中的模型,哪一个对数据拟合得更好?说明理由。
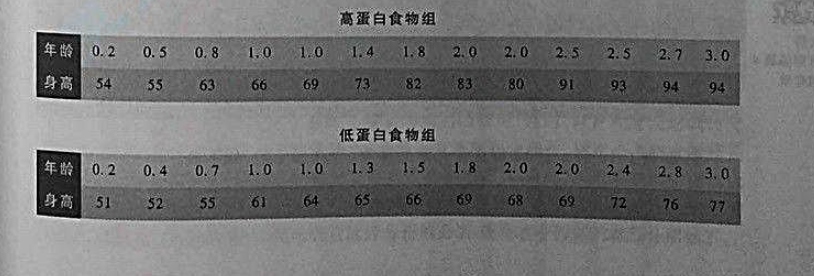
(1)分别用两组数据建立蛋白质高、低含量对婴儿身高的回归模型,解释所得结果。
(2)怎样检验蛋白质含量的高低对婴儿的生长有无显著影响?检验结果如何?
















