 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
如果你试图决定是否一个输入变量可能影响你的关键输出变量,你应该使用哪一个工具()
A.X-bar and R 图
B.P图
C.柏拉图
D.散点图
 答案
答案
D、散点图
 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.X-bar and R 图
B.P图
C.柏拉图
D.散点图
答案
D、散点图
如果结果不匹配,请 联系老师 获取答案
 更多“如果你试图决定是否一个输入变量可能影响你的关键输出变量,你应…”相关的问题
更多“如果你试图决定是否一个输入变量可能影响你的关键输出变量,你应…”相关的问题
A.你是否有时上网到深夜并为联结某个网站时间过长而着急?
B.你是否曾一再试图限制、减少或停止上网而不果?
C.你试图减少或停止上网时,是否会感到烦躁、压抑或容易动怒?
D.你是否曾因上网而危及一段重要关系或一份工作机会?
(i)你为什么会把这些数据归类为聚类样本?大致上,你预期能从一个典型学生得到大概多少次观测?
(ii)写出一个类似于教材方程(14.12)那样的模型,用到课率和其他特征去解释期终考试成绩。以s作为学生下标和c作为课程下标,对同一个学生哪个变量是不变的?
(iii)如果你把所有的数据混合起来并使用OLS,那么,对影响成绩和到课率的非观测学生特征,你正在做什么假定呢?SAT和学期前GPA在这方面扮演着什么角色呢?
(iv)如果你认为SAT和学期前GPA不足以刻画学生能力,你如何估计到课率对期终考试成绩的影响呢?
参考答案:


6.利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
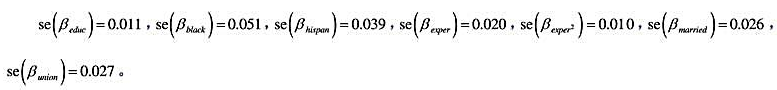
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
A.试图依靠一个反例推翻一个一般性结论。
B.试图诉诸个例在不相关的现象之间建立因果联系。
C.试图运用一个反例反驳一个可能性结论。
D.不当地依据个人经验挑战流行见解。
E.忽视了这种可能:她的祖父如果不常年吸烟可能更为长寿。
在近来的一篇论文中,埃文斯和施瓦布(EvansandSchwab,1995)研究了就读于天主教高中对将来读大学的概率所产生的影响。为具体起见,令college为二值变量,如果读大学则等于1,否则为0。令CahHS也为二值变量,如果就读于天主教高中则等于1.一个线性概率模型是:
college=β0+β1CathHS+其他因素+u
其中其他因素包括性别、种族、家庭收入和父母的受教育程度。
(i)为什么CathHS可能与u相关?
(ii)埃文斯和施瓦布拥有关于每个学生在大二时进行的标准化测验成绩数据。我们用这些变量能做些什么,以改进就读于天主教高中在其余条件不变情况下的估计值?
(iii)令CathRel为二值变量,若学生是天主教徒则等于1。讨论它成为前面方程中CathHS的一个有效的ⅣV所需要的两个要求。其中哪个可加以检验?
(iv)不足为奇,作为天主教徒对是否就读于一所天主教高中有显著的影响。你认为CathRel作为CathHS的工具变量令人信服吗?
A.敌视 互补
B.排斥 共鸣
C.提防 默契
D.诋毁 联系
刚从法学院毕业的学生的起薪中位数由下式决定:
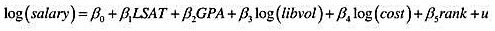
其中,LSAT’是整个待毕业年级LSAT成绩的中位数,GPA是该年级大学GPA的中位数,libvol是法学院图书馆的藏书量,cost是进入法学院每年的费用,而rank是法学院的排名(rank=1的法学院是最好的)。
(i)解释为什么我们预期βs ≤0。
(ii)你预计其他斜率参数的符号如何?给出你的理由。
(iii)使用LAWSCH85.RAW中的数据,估计出来的方程是
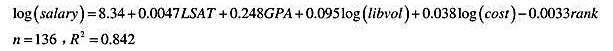
在其他条件不变的情况下,预计GPA中位数相差1分会导致薪水有多大差别?(用百分比报告你的答案。)
(iv)解释变量log(ibvol)的系数。
(v)你是否认为,应该进入一个排名更高的法学院?从预计的起薪来看,排名相差20位的价值有多大?
本题使用GPA2.RAW中的数据。
(i)考虑方程
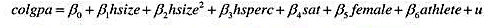
其中,colgpa表示累积的大学GPA,hsize表示高中毕业年级以百人计的规模,hsperc表示在毕业年级中学术排名的百分位,sat表示SAT综合分数,female是一个二值变量,而athlete也是一个运动员取值1的二值变量。你对这个方程中的系数有何预期?哪些你没有把握?
(ii)估计第(i)部分中的方程,并以通常的形式报告结果。估计运动员和非运动员之间GPA的差异是多少?它是统计显著的吗?
(ii)从模型中去掉sat并重新估计这个方程。现在,作为运动员的估计影响是多大?讨论为什么这个估计值不同于第(ii)部分的结论。
(iv)在第(i)部分的模型中,容许作为运动员的影响会因性别不同而不同。检验如下原假设:在其他条件不变的情况下,女生是否是运动员没有差别。
(v)sat对colgpa的影响会因性别不同而不同吗?讲出你的根据。
刚从法学院毕业的学生的起薪中位数由下式决定:
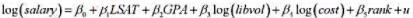
其中,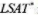 是整个待毕业年级LSAT成绩的中位数,GPA是该年级大学GPA的中位数,libvol是法学院图书馆的藏书量,cost是进入法学院每年的费用, 而是法学院的排名(rank=1的法学院是最好的) 。
是整个待毕业年级LSAT成绩的中位数,GPA是该年级大学GPA的中位数,libvol是法学院图书馆的藏书量,cost是进入法学院每年的费用, 而是法学院的排名(rank=1的法学院是最好的) 。
(i)解释为什么我们预期βs≤0。
(ii)你预计其他斜率参数的符号如何?给出你的理由。
(iii)使用LAWSCH85.RAW中的数据,估计出来的方程是
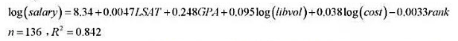
在其他条件不变的情况下,预计GPA中位数相差一分会导致薪水有多大差别?(以百分比回答。)
(iv)解释变量log(libvol) 的系数。
(v)你是否认为,应该进入一个排名更高的法学院?从预计的起薪来看,排名相差20位的价值有多大?
A.仍然能正确分类数据
B.不能正确分类
C.不确定
D.以上均不正确
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
















