 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
如果我使用数据集的全部特征并且能够达到100%的准确率,但在测试集上仅能达到70%左右,这说明:()。
A.欠拟合
B.模型很棒
C.过拟合
D.以上答案都不正确
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.欠拟合
B.模型很棒
C.过拟合
D.以上答案都不正确
如果结果不匹配,请 联系老师 获取答案
 更多“如果我使用数据集的全部特征并且能够达到100%的准确率,但在…”相关的问题
更多“如果我使用数据集的全部特征并且能够达到100%的准确率,但在…”相关的问题
A.级别划分较多的属性不会影响模型效果
B.在某些噪音较大的分类或回归问题上不会过拟合
C.每次学习使用不同训练集,一定程度避免过拟合
D.能够处理高纬度的数据,并且不做特征选择
A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征
D.查看相关性表,去除相关性最高的一些特征
A.可以处理高维度的属性,并且不用做特征选择
B.随机森林的预测能力不受多重共线性影响
C.也擅长处理小数据集和低维数据集的分类问题
D.能应对正负样本不平衡问题
A.!ip.addr==10.2.2.2 && !tcp.flags.syn==1
B.!ip.addr==10.2.2.2 && tcp.flags.syn!=1
C.ip.addr!=10.2.2.2 && !tcp.flags.syn==1
D.ip.addr==10.2.2.2 && tcp.flags.syn!=1
A.Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘
B.redis具有快速和数据持久化的特征
C.如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值
D.Redis如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能
A.负责嵌入式系统的全部软、硬件资源的分配、调度工作,控制并协调并发活动
B.具有一般操作的基本功能,如任务调度、同步机制、中断处理
C.它必须体现其所在系统的特征,能够通过装卸某些模块来达到系统所要求的功能
D.以库的形式提供给用户,用户可以通过操作系统的API使用嵌入式操作系统
ize) 方面的信息, 以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题, 只使用单身者数据(fsize=1)。
(i)数据集中有多少单身者?
(il)利用OLS估计模型
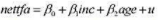
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H1:β2<1检验H0:β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归, inc的斜率估计值与第(ii) 部分的估计值有很大不同吗?为什么?
















