 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
MapReduce的输出文件个数由()决定。
A.map数量
B.reduce数量
C.随机生成
D.datanode数量
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.map数量
B.reduce数量
C.随机生成
D.datanode数量
如果结果不匹配,请 联系老师 获取答案
 更多“MapReduce的输出文件个数由()决定。”相关的问题
更多“MapReduce的输出文件个数由()决定。”相关的问题
算法设计:对于给定的组卷要求,计算满足要求的组卷方案.
数据输入:由文件input.txt提供输入数据.文件第1行有2个正整数k和n(2≤k≤20,k≤n≤1000),k表示题库中试题类型总数,n表示题库中试题总数.第2行有k个正整数,第i个正整数表示要选出的类型i的题数.这k个数相加就是要选出的总题数m.接下来的n行给出了题库中每个试题的类型信息.每行的第1个正整数p表明该题可以属于p类,接着的p个数是该题所属的类型号.
结果输出:将组卷方案输出到文件output.txt.文件第i行输出“i:”后接类型i的题号.如果有多个满足要求的方案,只要输出1个方案.如果问题无解,则输出“NoSolution!".


算法设计:对于给定的方格棋盘,按照取数要求找出总和最大的数.
数据输入:由文件input.txt提供输入数据.文件第1行有2个正整数m和n,分别表示棋盘的行数和列数.接下来的m行,每行有n个正整数,表示棋盘方格中的数.
结果输出:将取数的最大总和输出到文件output.txt.


 .m处理器问题要求的是
.m处理器问题要求的是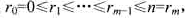 ,将数据包序列划分为m段:
,将数据包序列划分为m段: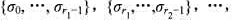
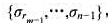 使
使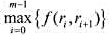 达到最小.式中,
达到最小.式中,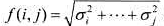 是序列
是序列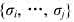 的负载量.
的负载量.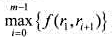 的最小值称为数据包序列
的最小值称为数据包序列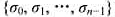 的均衡负载量.
的均衡负载量.
算法设计:对于给定的数据包序列,计算m个处理器的均衡负载量.
数据输入:由文件input.txt给出输入数据.第1行有2个正整数n和m.n表示数据包个数,m表示处理器数.接下来的1行中有n个整数,表示n个数据包的大小.
结果输出:将计算的处理器均衡负载量输出到文件output,txt,且保留2位小数.

问题描述:给定正整数序列x1,x2,…,xn要求:
①计算其最长递增子序列的长度s.
②计算从给定的序列中最多可取出多少个长度为s的递增子序列.
③如果允许在取出的序列中多次使用x1和xn,则从给定序列中最多可取出多少个长度为s的递增子序列.
算法设计:设计有效算法完成①、②、③提出的计算任务.
数据输入:由文件input.txt提供输入数据.文件第1行有1个正整数n,表示给定序列的长度.接下来的1行有n个正整数x1,x2,...,xn,
结果输出:将任务①、②、③的解答输出到文件output.txt.第1行是最长递增子序列的长度s.第2行是可取出的长度为s的递增子序列个数.第3行是允许在取出的序列中多次使用x1和xn时可取出的长度为s的递增子序列个数.

问题描述:设有n个程序{1,2,...,n}要存放在长度为1的磁带上.程序i存放在磁带上的长度是li(1≤i≤n).程序存储问题要求确定这n个程序在磁带上的一个存储方案,使得能够在磁带上存储尽可能多的程序.
算法设计:对于给定的n个程序存放在磁带上的长度,计算磁带上最多可以存储的程序数.
数据输入:由文件input.txt给出输入数据.第1行是2个正整数,分别表示文件个数n和磁带的长度L.接下来的1行中,有1个正整数,表示程序存放在磁带上的长度.
结果输出:将计算的最多可以存储的程序数输出到文件output.txt.

问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及d个约束字符串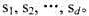 多子串排斥约束的最长公共子序列问题就是要找出x和y的不含为其子串的最长公共子序列
多子串排斥约束的最长公共子序列问题就是要找出x和y的不含为其子串的最长公共子序列
算法设计:设计一个算法,找出给定序列x和y的不含为其子串的最长公共子序列.
数据输入:重文件input.txt提供输入数据.文件的第1行中给出正整数d,表示约束字符串个数.接下来的2行分别给出序列x和y.最后d行的每行给出一个约束字符串.
结果输出:将计算出的x和y的不含为其子串的最长公共子序列输出到文件output.txt中.文件的第1行输出最长公共子序列.第2行输出最长公共子序列的长度.

MapReducemain接口设置和运行命令分别如下,请问MapReduce的输入文件为()
Publicvoidmain(string[]args)
{
String[]otherArgs=newGeneriOptionsParser(conf,args).getRemainingArgs();
FileInputFormat.addInputPath(job,newPath(otherArgs[0]));
FileOutputFormat.setOutputPath(job,newPath(otherArgs[1]));
}
命令:hadoopjarWordCount.jar/user/hadoopfs/test.txt/user/hadoopfs/out
A、WordCount.jar
B、/user/hadoop
C、/user/hadoopfs/test.txt
D、/user/hadoopfs/out
A.<"hello",1,1>、<"hadoop",1>和<"world",1>
B.<"hello",2>、<"hadoop",1>和<"world",1>
C.<"hello",<1,1>>、<"hadoop",1>和<"world",1>
D.<"hello",1>、<"hello",1>、<"hadoop",1>和<"world",1>
















