 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在随机效应模型中,定义复合误差为,其中ait与uit无关,而且uit有常方差并且是序列无
在随机效应模型中,定义复合误差为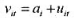 ,其中ait与uit无关,而且uit有常方差
,其中ait与uit无关,而且uit有常方差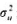 并且是序列无关的。定义
并且是序列无关的。定义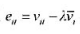 ,其中λ由式(14.10)给出。
,其中λ由式(14.10)给出。
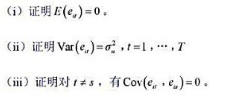
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
在随机效应模型中,定义复合误差为,其中ait与uit无关,而且uit有常方差并且是序列无关的。定义,其中λ由式(14.10)给出。
如果结果不匹配,请 联系老师 获取答案
 更多“在随机效应模型中,定义复合误差为,其中ait与uit无关,而…”相关的问题
更多“在随机效应模型中,定义复合误差为,其中ait与uit无关,而…”相关的问题
有计划上大学的中学高年级学生。
(Ⅰ) 假设你有权进行一项控制实验。请说明为了估计hours对sal的引致效应, 你将如何构建实验。
(Ⅱ) 考虑一个更加实际的情形, 即由学生选择在备考课程上花多少时间, 而你只能随机地从总体中抽出sat和hours的样本。将总体模型写作如下形式:
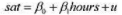
其中,与通常带截距的模型一样, 我们可以假设E(u)=0。列举出至少两个u中包含的因素。这些因素与hours可能呈正相关还是负相关?
(III)在(Ⅱ)的方程中,如果备考课程有效,那么β1的符号应该是什么?
(Ⅳ)在(Ⅱ)的方程中,β0该如何解释?
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
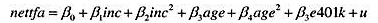
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
本题利用401KSUBS.RAW中的数据。
(i) 计算样本中nettfa的平均值、标准差、最小值和最大值。
(ii) 检验假设平均nettfa不会因为401(k) 资格状况而有所不同, 使用双侧对立假设。估计差异的美元数量是多少?
(iii)根据计算机习题C7.9的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e40lk作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv) 在第(iii) 部分估计的模型中, 增加交互项e401k·(age-41) 和e401k·(age-41)2 。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi) 现在, 从模型中去掉交互项, 但定义5个家庭规模虚拟变量:fsize l, j size2,f size 3, f size 4和f size 5。对有5个或5个以上成员的家庭, fsize 5等于1。在第(iii) 部分估计的模型中, 增加家庭规模虚拟变量, 记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii) 现在, 针对模型
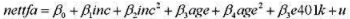
在容许截距不同的情况下, 做5个家庭规模类别的邹至庄检验。约束残差平方和SSR, 从第(vi) 部分得到,因为那里回归假定了相同斜率。无约束残差平方和SSRUR=SSR1+SSR2 +…+SSR5 , 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
设A={x|x∈R∧x≠0,1}。在A上定义6个函数如下:
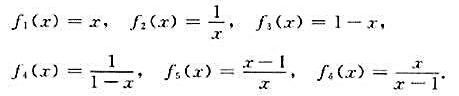
V=<S,°>,其中S={f1,f2,...,f6},°为函数的复合.。
(1)给出V的运算表。
(2)说明V的幺元和所有可逆元素的逆元:
(i)u中包含什么样的因素?它们可能与受教育程度相关吗?
(ii)简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
A.X与Y有线性关系(多项式关系)
B.模型误差在统计学上是独立的
C.误差一般服从0均值和固定标准差的正态分布
D.X是非随机且测量没有误差的
A.t时刻的基本正常负荷分量
B.t时刻的天气敏感负荷分量
C.t时刻的特别事件负荷分量
D.t时刻的随机负荷分量
假设过程{(xt,yt):t=0,1···},满足方程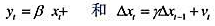 其中,
其中,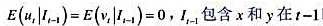 时期及此前的所有信息β≠0,且|y|<1[于是xt并因而yt是((1)]。证明:这两个方程意味着如下形式的一个误差修正模型:
时期及此前的所有信息β≠0,且|y|<1[于是xt并因而yt是((1)]。证明:这两个方程意味着如下形式的一个误差修正模型:
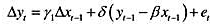
其中,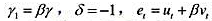 。(提示:首先从第一个方程的两边减去yt-1.然后在右边加上并减去一个βxt-1,并重新整理。最后,利用第二个方程得到包含Δxt-1的误差修正模型。)
。(提示:首先从第一个方程的两边减去yt-1.然后在右边加上并减去一个βxt-1,并重新整理。最后,利用第二个方程得到包含Δxt-1的误差修正模型。)
A.讲座上听众们都认真听讲,全然不顾外面电闪雷鸣
B.生日聚会上他从一个话题转移到另一个话题,侃侃而谈
C.很少有人注意到83版的《射雕英雄传》中有跑龙套的周星驰
D.婚礼上来宾们把目光都投向了新郎新娘
















