 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
假设我们想估计若干个变量对年储蓄的影响,并且我们拥有1990年1月31日和1992年1月31日所收集的
个人面板数据。如果我们包括了一个1992年的年度虚拟变量并利用一阶差分,那么我们还能在原模型中包含年龄变量吗?试解释。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“假设我们想估计若干个变量对年储蓄的影响,并且我们拥有1990…”相关的问题
更多“假设我们想估计若干个变量对年储蓄的影响,并且我们拥有1990…”相关的问题
本题使用GPA2.RAW中的数据。
(i)考虑方程
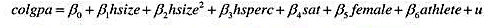
其中,colgpa表示累积的大学GPA,hsize表示高中毕业年级以百人计的规模,hsperc表示在毕业年级中学术排名的百分位,sat表示SAT综合分数,female是一个二值变量,而athlete也是一个运动员取值1的二值变量。你对这个方程中的系数有何预期?哪些你没有把握?
(ii)估计第(i)部分中的方程,并以通常的形式报告结果。估计运动员和非运动员之间GPA的差异是多少?它是统计显著的吗?
(ii)从模型中去掉sat并重新估计这个方程。现在,作为运动员的估计影响是多大?讨论为什么这个估计值不同于第(ii)部分的结论。
(iv)在第(i)部分的模型中,容许作为运动员的影响会因性别不同而不同。检验如下原假设:在其他条件不变的情况下,女生是否是运动员没有差别。
(v)sat对colgpa的影响会因性别不同而不同吗?讲出你的根据。
令math10表示密歇根州高中学生在一次标准化数学考试中的及格百分比(也可参见例4.2)。我们感兴趣的是估计每个学生的支出对其数学成绩的影响。一个简单的模型是
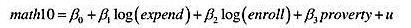
其中,poverty表示贫困生的比例。变量Inchprg表示学校有资格享受联邦政府午餐资助计划的学生比例。为什么它是povert的一个合适的代理变量?
(ii)下表包含了有和没有Inchprg作为解释变量时的OLS估计值。解释为什么支出对mathl0的影响在列(2)比在列(1)要低。列(2)中的这种影响在统计上仍大于1吗?
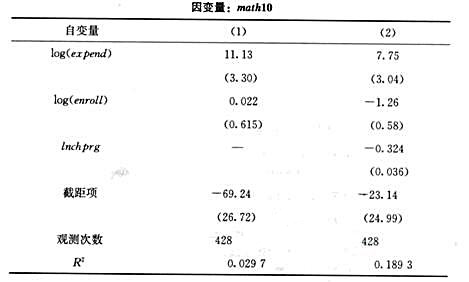
(iii)在其他条件相同的情况下,越大的学校通过率越低吗?请解释。
(iv)解释列(2)中Inchprg的系数。
(v)你如何理解R从列(1)到列(2)的显著提高?
利用得自格雷迪(Graddy,1995)的数据集FISH.RAW。这个数据集也曾用于第12章的计算机练习C9.现在,我们用它估计一个鱼肉需求函数。
(i)假定每个时期均衡的鱼肉需求方程可写成
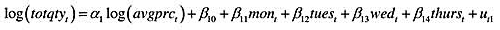
所以容许需求在一周中的每一天都有所不同。把价格变量视为内生的,一致地估计需求方程参数还需要什么额外信息?
(ii)变量wavet和wave3t度量了过去几天的海浪高度。为了在估计需求方程时将wave2t和wave3t用作log(avgprc)的Ⅳ,我们还需要哪两个假定?
(ii)将log(avgprc)对周工作日虚拟变量和两个浪高指标进行回归。wave2t和wave3t联合显著吗?这个检验的p值是多少?
(iv)现在,用2SLS估计需求方程。需求价格弹性的95%置信区间是什么?所估计的弹性合理吗?
(v)求2SLS的残差ut。在用2SLS估计需求方程时增加一个滞后ut-1记住,用ut-1作为自己的工具。需求方程误差中有AR(1)序列相关的证据吗?
(vi)给定供给方程明显取决于海浪变量,为了估计供给价格弹性,我们需要哪两个假定?
(vii)在log(avgprct)的约简型方程中,周工作日虚拟变量联合显著吗?你对能够估计供给弹性有何结论?
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
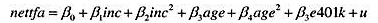
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
利用GPA2.RAW中的数据,可估计出如下方程:

变量sat是SAT的综合分数,hsize是以百人计的学生所在高中毕业年级的学生规模,female是一个性别虚拟变量,而black是一个种族虚拟变量(黑人取值1,其他人则取值0)。
(i)有很强的证据支持模型中应该包括hsize”吗?从这个方程来看,最优的高中规模是什么?
(ii)保持hsize不变,非黑人女性和非黑人男性之间SAT分数的估计差异是多少?这个估计差异的统计显著性如何?
(iii)非黑人男性和黑人男性之间SAT分数的估计差异是多少?检验其分数没有差异的原假设,备择假设是他们的分数存在差异。
(iv)黑人女性和非黑人女性之间SAT分数的估计差异是多少?为了检验这个差异的统计显著性,你需要怎么做?
利用JTRAIN.RAW,以确定工作培训津贴对每个雇员工作培训小时数的影响。三年的基本模型是:

(i)用固定效应法估计方程。在此估计中利用了多少个企业?如果每个企业都有这三年的所有变量数据(特别是hrsemp的数据),总观测个数会是多少?
(ii)解释grant的系数并评论它的显著性。
(iii)grant-1不显著有什么惊人之处吗?请解释。
(iv)平均地说,更大的企业为其职工提供了更多还是更少的培训?差别有多大?(比方说,职工多10%的企业,培训的平均小时数增多或减少了多少?)
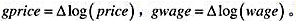 ]利用WAGEPRC.RAW中的月度数据,我们估计了如下分布滞后模型:
]利用WAGEPRC.RAW中的月度数据,我们估计了如下分布滞后模型: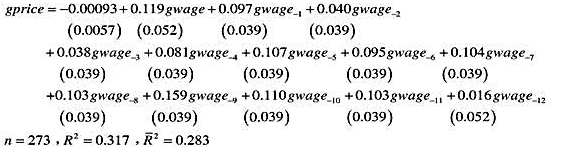
(i)描述估计的滞后分布。gwage的哪一个滞后对gprice的影响最大?哪一个滞后的系数最小?
(ii)哪些滞后的:统计量小于2?
(iii)估计的长期倾向是多少?它与1有很大不同吗?解释本例中的LRP告诉了我们什么?
(iv)你将用什么样的模型来直接求出LRP的标准误?
(v)你将怎样检验gwage的6阶以上滞后的联合显著性?F分布的df是多少?(注意:你又失去了6个观测。)
使用CEOSAL2.RAW中的数据得出下表:

变量mktval为企业的市场价值,profmarg为利润占销售额的百分比,ceoten为其就任当前公司CEO的年数,而comten则是其在这个公司任职的总年
数。
(i)评论profiarg对CEO薪水的影响。
(ii)市场价值是否具有显著影响?试解释你的结论。
(iii)解释ceoten和comten的系数。这些变量是统计显著的吗?
(iv)你如何解释在其他条件不变的情况下,你在这个公司任职时间越长,你的薪水则越低?
A.相对无害的化学物质在水中不相互反应形成有害的化合物。
B.河道内的水流动得很快,能确保排放到河道的化学物质被快速地散开。
C.没有完全禁止向河道内排放化学物质。
D.那些持有许可证的人通常不会向河道内排放达到许可证所允许的最大量的化学物质。
















